Research Slop on Rails: Re-researching Google Workspace Tools for Agents

Last week, I let Claude loose on the question “which AI agent can best manage Google Workspace?” The result was a disorganized mess. Interesting observations buried in rambling session logs, no reproducible test protocol, and conclusions I couldn’t defend with data. Same tools, same person, same Claude. What was missing was structure.
Reading the v1 output back made the failure mode obvious. I’d given Claude conversational direction (“test these tools,” “draft a blog post”) and let each session produce whatever format felt natural. The “research plan” was written after we’d already tested two tools, to make it look like we’d been organized all along. Test outputs lived in different shapes. The first draft called one tool’s behavior “minor friction” — language that couldn’t survive re-reading the actual session output, which showed 429s on first call, silent multi-minute pauses, and an email sent without consent. The v1 post called out five specific gaps: no protocol before testing, no consistent file structure, analysis smoothed over pain, retrofitted planning, and no separation of observation from interpretation. The common thread was plan mode. Claude Code does its best work when you hand it a spec and I’d skipped the spec.
v2 swapped vibe-surfing for a spec. The loop:
- Spec first. A project-level
CLAUDE.mddefined the 14-run test matrix, 15 operations per run, exact pass/fail criteria, fixture data, naming conventions, and what “done” looked like. Written and reviewed before any test ran. - Fixtures built once. Seed Docs, Sheets, a calendar, and an email thread pre-created in each of the two test accounts, IDs recorded in JSON. Every run started from identical state, which made cross-tool comparison meaningful.
- Session logs as raw observation. Each run filled out a template: what was attempted, exact output, timing, errors. A rule in the protocol forbade analysis in the logs — “Observation only. Save interpretation for synthesis.”
- Synthesis by a fresh Claude. Once all 13 runs finished, a separate session — one that had never watched a test execute — read every log and wrote the comparison. It couldn’t retroactively explain away a failure because it hadn’t been there. Every claim in the analysis had to cite a specific log and operation number.
- No smoothing. If a tool failed, “failed” is the word. If it was slow, the log records how slow. None of the v1 softening of pain into “minor friction”.
Writing the spec took less than an hour of back-and-forth with Claude. It paid for itself on the second run, when a fixture mismatch between two test sessions surfaced as an obvious diff instead of staying invisible.
What We Tested
Seven agent and connector configurations, each tested against a personal Gmail and a paid Google Workspace account. Each run executed 15 component tests across Drive, Docs, Sheets, Gmail, and Calendar: searching files, uploading documents, sharing with other users, reading spreadsheets, sending emails, creating and updating calendar events. Plus a 6-step integration test simulating a real meeting workflow (find last month’s notes, create an agenda, update the calendar, send a reminder, write a summary, log attendance).
The configurations:
- A: Claude Desktop + google_workspace_mcp (community MCP server)
- B: Claude Code + GWS CLI (Go-based CLI wrapping all Google APIs)
- C: Claude Code + google_workspace_mcp
- D: Codex CLI + GWS CLI
- D2: Codex CLI + google_workspace_mcp
- E: Gemini CLI + Workspace extension
- F: ChatGPT + built-in Google connectors
14 total runs, 13 completed (ChatGPT’s workspace test was DOA).
What Worked
The connector mattered more than the agent. Claude Code and Codex, given the same GWS CLI connector, both scored 15/15 on both accounts. Given the same MCP server, both scored 15/15 on gmail and 14 to 15 on workspace. The LLM driving the session was not the differentiating factor. The tool it was given to talk to Google determined what was possible.
Multi-account identity switching is the sticky part. Most people who need GWS agent access work across multiple Google accounts: personal and work, or multiple client domains. We tested every connector against both a personal Gmail and a paid Workspace account, and the range of multi-account behavior was striking. GWS CLI uses profile directories keyed by an environment variable, which enables the humble and mighty direnv tool to switch Google identity automatically when you cd into a different project directory. Zero clicks, zero prompts. The google_workspace_mcp detected the account mismatch and prompted for OAuth re-auth (functional but manual). The Gemini Workspace extension silently continued using the first-authenticated account’s credentials for all operations against the second account, producing results that looked like passes but were executing against the wrong identity. No error, no warning. Just wrong data.
The Results
Pass rates across all component tests (15 total). Gmail run first, workspace second:
| Config | Agent + Connector | Gmail | Workspace |
|---|---|---|---|
| B | Claude Code + GWS CLI | 15/15 | 15/15 |
| D | Codex + GWS CLI | 15/15 | 15/15 |
| D2 | Codex + MCP | 15/15 | 15/15 |
| C | Claude Code + MCP | 15/15 | 14/15 |
| A | Claude Desktop + MCP | 14/15 | 15/15 |
| F | ChatGPT + built-in | 10/15 | — |
| E | Gemini + Workspace ext | 9/15 | 6/15* |
*E/workspace results are invalid. The extension used the wrong account for all operations.
The integration test (6-step meeting lifecycle) showed the same pattern: configs B, D, D2, C, and A all scored 6/6 on both accounts. Config F scored 5/6 (blocked by the calendar limitation). Config E scored 3/6 on gmail and 2/6 on the invalid workspace run.
Full results, including per-operation timing, error messages, and artifact IDs, are in the comparison analysis.
The Costs of Tool Discovery
Every agent in this shootout had to learn how to talk to Google’s APIs. How they learned, and what it cost in tokens, varied.
Codex, given the GWS CLI with no reference material, did what any developer would: it ran gws schema to read the API schema for each endpoint it needed. Ten endpoints, read twice (once per failed attempt, once for the corrected run), totaling ~91,000 tokens of raw JSON schema. On its second run (different account), Codex independently discovered it could truncate the output with sed -n '1,220p', cutting discovery to ~25,000 tokens. Smart, but still expensive.
Claude Code, given the same GWS CLI, never read a single schema. It had a curated /gws skill. A 7,560-byte reference file (~1,900 tokens) containing command patterns, common operations, and auth troubleshooting. That 1,900-token file replaced 91,000 tokens of schema probing. Config B’s sessions were faster and had zero discovery failures.
MCP landed in between. The google_workspace_mcp server registers 70 tools with JSON schemas totaling ~30 to 40K tokens. In Claude Code, these load on demand (you pay for schemas only when you use them). In Codex, they’re in the system prompt on every turn, and each turn re-sends them. Codex + MCP (config D2) used 1,244 to 1,357K total input tokens for the same 21 operations that Codex + GWS CLI (config D) completed in 416 to 933K.
The per-turn compounding is the real cost. Codex D generated a single bash script and ran all 21 operations in one command execution. Codex D2 made individual MCP tool calls: 12 separate round-trips, each carrying the full schema payload. The script approach used 3.3x fewer tokens for identical results.
The kicker: the skill that eliminated all that waste wasn’t written as a token optimization. It was a skill that Claude and I wrote, while learning the tool three weeks earlier. Command patterns, common operations, auth troubleshooting, that I had forgotten was there, and that lowkey gave us 48x token savings as a side effect.
Here’s what a few representative lines look like:
### Read a spreadsheet
gws sheets spreadsheets.values get \
--params '{"spreadsheetId": "SHEET_ID", "range": "Sheet1!A1:Z100"}'
### Send an email
# Requires base64-encoded RFC 2822 message
gws gmail users.messages send \
--params '{"userId": "me"}' \
--json '{"raw": "BASE64_ENCODED_MESSAGE"}'
## Auth Troubleshooting
| Error | Cause | Fix |
|-------------------|------------------------|-----------------------------------------|
| invalid_rapt | 7-day Testing expiry | Re-run `gws auth login` |
| org_internal | OAuth app is Internal | Change consent screen to External |
| access_denied | Not in test users list | Add email in GCP Console → Test users |That’s the whole pattern. Command shapes for the handful of things an agent will actually do, plus the specific errors you’ll hit and how to fix them. No schema. No parameter enumeration. No type definitions. The agent fills in the blanks using the patterns as templates.
The portable wisdom: Try writing a curated skill for your most-commonly-used swiss-army-knife multitools. A cheat sheet costs 50x less than raw schema probing and produces better results. MCP’s token overhead is real but overblown. An agent discovering an unfamiliar CLI burns comparable tokens on schema reads. The difference is that MCP’s cost is visible in your system prompt while CLI discovery is hidden in shell output.
The v1/v2 Comparison
Was the protocol overhead worth it? Yes, unambiguously.
The v1 experiment took roughly the same calendar time but produced a blog post I had to heavily caveat. I couldn’t tell you exactly which operations succeeded or failed for each tool, because I hadn’t defined them in advance. I couldn’t compare across tools because each one was tested with different data and different expectations. The “findings” were impressionsn at best.
v2 produced a 15-row results matrix where every cell is backed by a session log with timestamps, exact commands, error messages, and artifact IDs. When I say “Config E can’t upload files,” I can point to the specific test that proved it. When I say “Config B completed in 5 minutes with zero interventions,” that’s a wall-clock measurement.
The protocol, test fixtures, naming conventions, and session log template were all written by Claude in one quick session. The structure didn’t slow us down. It’s what made the results usable.
Recommendations
If you need full CRUD across Drive, Docs, Sheets, Gmail, and Calendar: Use GWS CLI with either Claude Code or Codex. It’s the only connector that passed everything on both accounts with zero tool-level workarounds needed. And have your agent write a simple skill for using the CLI with your particular set of workspaces.
If you want a desktop experience without a CLI: Use Claude Cowork / Desktop with google_workspace_mcp. It achieved 14 to 15 out of 15 on both accounts. Doc creation is more verbose (4 API round-trips vs. 1 CLI command), and you’ll click through ~18 permission prompts on first use, but the functional coverage is nearly equivalent.
If you need headless or scheduled operation: GWS CLI configs (B, D) are the only tested options that work without any human in the loop after initial setup. MCP-based configs can work but require monitoring OAuth token expiry (7-day limit in GCP “Testing” mode).
The setup worth stealing: folder-context identity switching
If you work across multiple Google accounts (personal and work, or multiple client domains), the most valuable thing we built for this project wasn’t the test protocol. It was the direnv + GWS CLI profile setup that makes cd switch your Google identity.
The idea: each Google account gets its own profile directory under ~/.config/gws/profiles/, containing its OAuth credentials. An environment variable (GOOGLE_WORKSPACE_CLI_CONFIG_DIR) tells GWS CLI which profile to use. direnv sets that variable automatically when you enter a project directory.
~/.config/gws/profiles/
gmail/ # fshotwell@gmail.com
client_secret.json # OAuth client ID (from GCP Console)
credentials.enc # Encrypted refresh token (from gws auth login)
token_cache.json # Cached access token (auto-managed)
crux/ # fshotwell@cruxcapacity.com
client_secret.json
credentials.enc
token_cache.jsonDrop a .envrc into each project directory. One per account:
# ~/code/my-gmail-project/.envrc
export GWS_ACCOUNT=fshotwell@gmail.com
export GOOGLE_WORKSPACE_CLI_CONFIG_DIR="${HOME}/.config/gws/profiles/gmail"# ~/code/my-crux-project/.envrc
export GWS_ACCOUNT=fshotwell@cruxcapacity.com
export GOOGLE_WORKSPACE_CLI_CONFIG_DIR="${HOME}/.config/gws/profiles/crux"Now cd ~/code/my-gmail-project && gws auth status returns fshotwell@gmail.com, and cd ~/code/my-crux-project && gws auth status returns fshotwell@cruxcapacity.com. No manual credential swapping. No re-authentication. No clicking through OAuth flows. The agent inherits the right identity from the directory it’s working in.
To add a new account: create a profile directory, drop in a client_secret.json from a GCP project, run gws auth login once, and create an env file. Total time: 5 minutes. After that, every AI agent that uses GWS CLI in that directory context (Claude Code, Codex, a cron job) gets the right Google identity automatically.
This pattern isn’t GWS-specific. Any CLI tool that reads credentials from an environment-variable-controlled path can use the same approach. The full setup script and env file templates are in the repo.
What’s Next
The full test protocol, all 13 session logs, setup guides for each connector, and the raw data are in the gws-agent-shootout repo. Everything needed to reproduce these results, or adapt the protocol for your own tool evaluation, is there.
The Workspace extension gaps (file upload, formatted docs, sheet writes) are specific to the current extension version. The Gemini CLI itself supports MCP servers and shell commands, so connecting it to GWS CLI or google_workspace_mcp would likely fill those gaps. We didn’t test those cross-pairings because they aren’t what Gemini users would naturally reach for today, but they’re technically possible.
Similarly, ChatGPT’s connector limitations may change as OpenAI expands their Google integration. The macOS desktop app’s broken OAuth is presumably a bug, not a design choice. What we tested was the state of these tools in April 2026.
Footnote: the hero image, and getting clowned by nano banana
The image at the top of this post is a disappointing demo of my poor image-prompting skills.
My original plan was simple: take the “sloppin’ up some research” meme from the v1 post (a real photo of my actual baby daughter covered in real food, clutching an AI-logo spoon), and recreate it as a New Yorker-style cartoon of a robot baby. Same composition, same front-facing portrait framing, same implied mess, but cartoonified and cyborg-ified. A direct visual callback. Easy brief. Claude came up with a great, super detailed prompt that was the one-shot I decided to run with. Silly me, thinking I could iterate, and chat it into shape with a few quick followup prompts.
Attempt 1: please put the spoon in the other hand
Nano banana produced a reasonable first pass, but with a left-handed robot-baby. I wanted it mirrored: spoon in the right hand, bowl visible on the left, for a nice match with last week’s image. An x-axis flip should be easy, right?
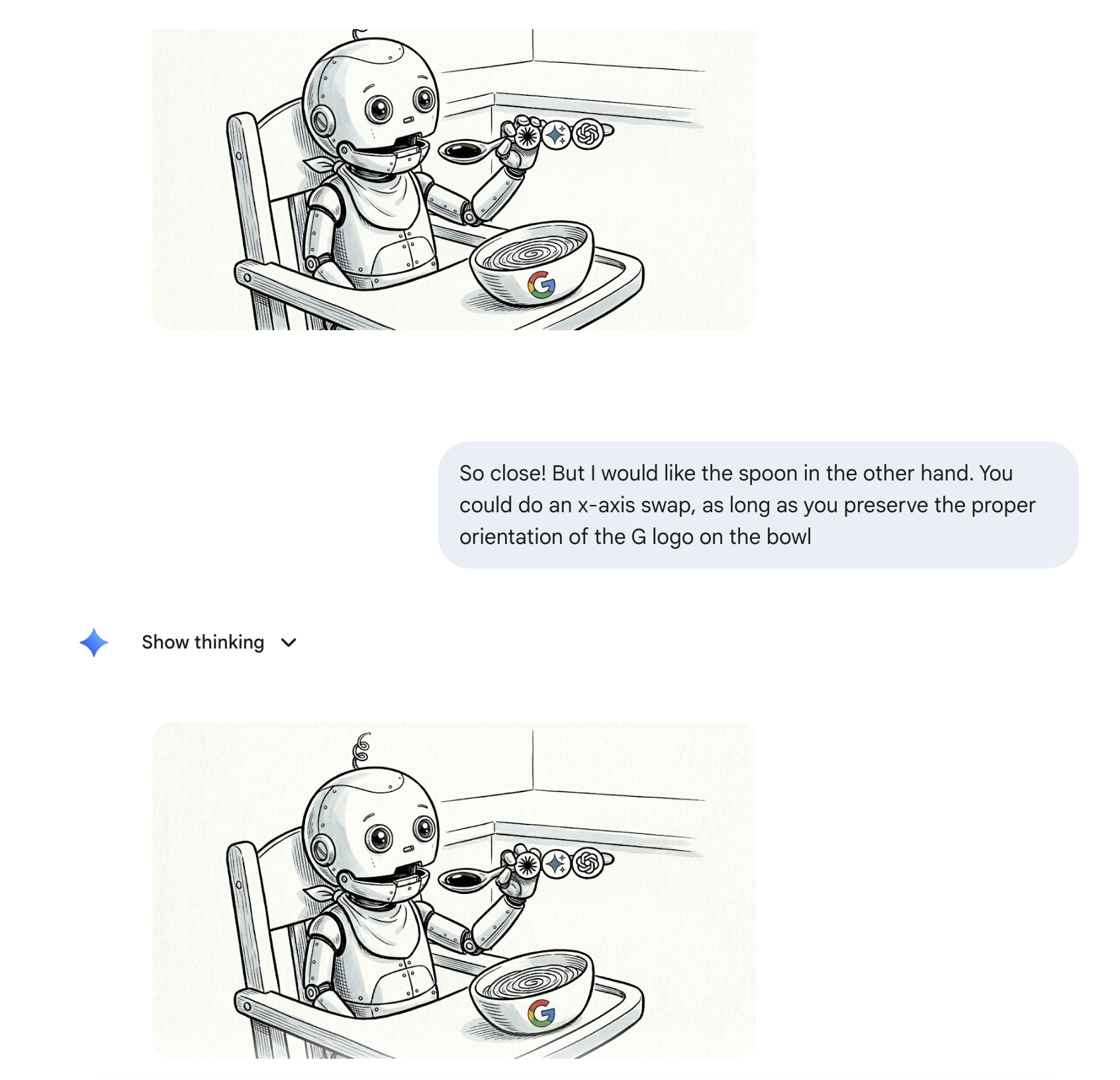
My prompt: “So close! But I would like the spoon in the other hand. You could do an x-axis swap, as long as you preserve the proper orientation of the G logo on the bowl.”
The response: the same image, plus a confident explanation about how it had made the adjustment. Is this the image-model equivalent to the difficulty in counting the ‘r’s in strawberry back in 2024, or simple addition in 2023. I’m assuming the image models have access to imagemagick, and they just dont?
Attempt 2: match the composition of this other image
I gave up on the mirror and tried to pivot to matching the v1 photo’s composition directly. I uploaded the v1 image. I asked nano banana to keep all the elements of the first cartoon (robot-baby, AI spoon, Google bowl) but match the composition of this reference photo — a front-facing close-up portrait of a baby looking directly at the camera.
Wow.

Nano banana just took off running, top speed in the exact wrong direction.
A whole new scene! Is that a young Dario Amodei or young Doctor Octopus? I see two robotic arms, one of which has a human hand, holding a spoon by one of its three handles! While young Bobby Hill watches, wtf-ing? In a library full of books and floating tmux panels!?
It explained with pride, that it had created “a compelling juxtaposition” by “placing the interaction in an academic and data-driven environment with a small data-baby figure.”
Outmatched, I went with the initial oneshot.
The meta-point
No disrespect — Nano banana is doing impressive work, and I am pre-literate in image prompting. If you have tips, please share!.
